| |
|||
| HSG |
|
Beispiel
Die Grammatik
S --> T*S S --> T T --> i
führt nach dem LR(0)-Verfahren zu der Syntaxanalyse-Tabelle
* i $ | S T
0 s3 | 1 2
1 r0 r0 r0 |
2 s4/r2 r2 r2 |
3 r3 r3 r3 |
4 s3 | 5 2
5 r1 r1 r1 |
Diese Tabelle kann wesentlich verbessert werden, wenn man berücksichtigt, dass bei einer Reduktion keineswegs jedes terminale Symbol dem reduzierten Nonterminal folgen kann, sondern nur die Elemente der entsprechenden FOLLOW-Menge.
Zitat aus Dr. Kunert, LR(k)-Analyse für Praktiker, S.26
Bevor reduziert wird, fragt sich ein SLR(1)-Parser, ob das Symbol, was direkt hinter der erkannten rechten Seite steht, überhaupt dem Metasymbol auf der linken Seite folgen darf und reduziert nur in diesem Fall mit dieser Regel. Man benötigt also zu jedem Metasymbol eine Menge aller Symbole, die diesem folgen können - und genau diese Menge wird zufälligerweise (!?!) durch die bereits bekannte FOLLOW-Menge beschrieben.
Mit den Compilertools ct1.py erhält man
>>> G16
[('S', 'T*S'), ('S', 'T'), ('T', 'i')]
>>> FOLLOW_Mengen(G16)
{'S': {'$'}, 'T': {'*', '$'}}
Da hier FOLLOW(S') = FOLLOW(S) = {$} kann in Zeile 1 nur in der Spalte $ r0 stehen, die restlichen Einträge müssen gelöscht werden. Ebenso darf in Zeile 2 r2 nur in der Spalte $ stehen. Damit löst sich der shift-reduce-Konflikt bei [2,*]. In Zeile 3 muss r3 wegen FOLLOW(T) = {*,$} in der Spalte i gelöscht werden. Schließlich kann in Zeile 5 r1 nur der Spalte $ stehen.
* i $ | S T
0 s3 | 1 2
1 r0 |
2 s4 r2 |
3 r3 r3 |
4 s3 | 5 2
5 r1 |
Die gleiche Tabelle wird von JFLAP erstellt. Nur dass wie üblich statt r0 acc eingetragen wurde.
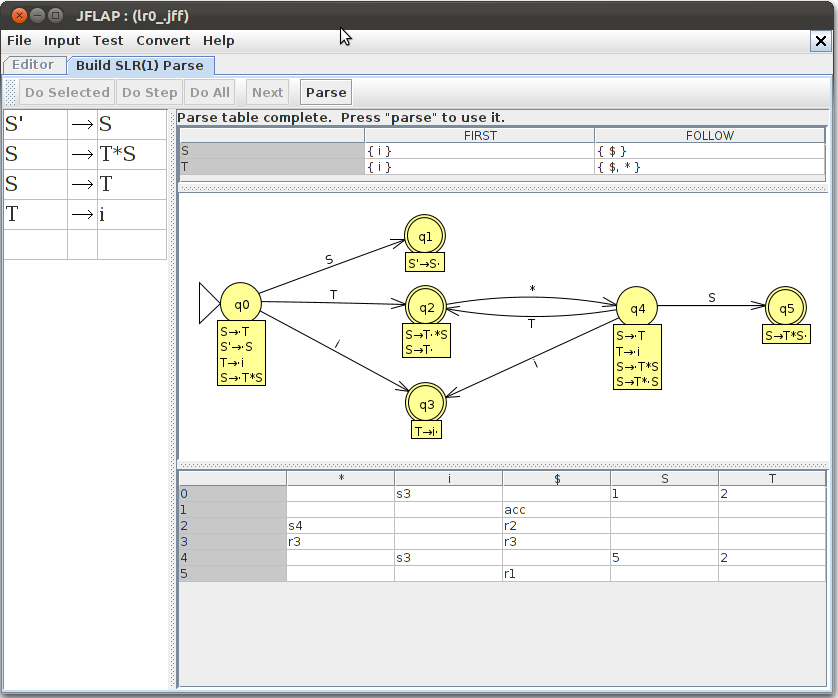
Beispiel 1
Arbeit mit einer Syntaxanalysetabelle (parse table)
Gib in jflap obenstehende Grammatik ein.
Wähle Input/Build SLR(1) Parse Table und lasse - mehrfach - die Eingabe aaaab abarbeiten.
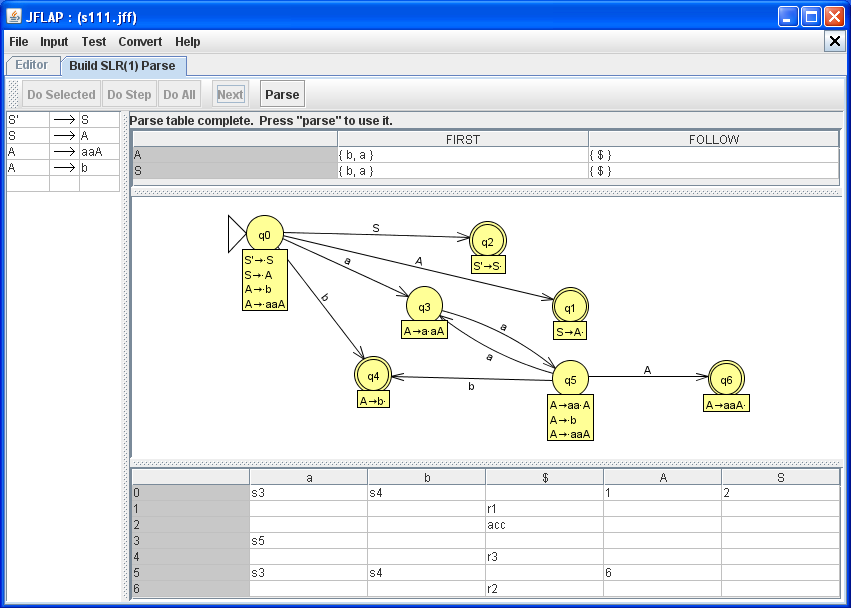
Aufgabe
Arbeite mit Hilfe von jflap gründlich die Seiten 13-16 von LR(k)-Analyse für Pragmatiker von Dipl.-Inf. Andreas Kunert durch. Insbesondere ist das angegebene Beispiel
S → Sb S → bAa A → aSc A → a A → aSb Eingabe: baab
nachzuvollziehen. shift und reduce müssen sicher verstanden sein! g1.jff
Arbeitsweise des Analyse-Automaten
Pseudocode nach: Compilerbau, Michael Jäger, S.104
push(s0) (lege die Nummer des Startzustand auf den Stack);
acc := false;
while not acc do
begin
sei Z Zustand oben auf dem Stack
sei t das nächste Token
case Aktionstabelle[Z][t] of
shift(n) : begin
push(t);
push(n);
lese nächstes Token t;
end;
reduce(r) : begin
sei A → β die Produktion mit der Nummer r;
sei k die Länge von β
pop 2k Elemente (hole 2k Elemente vom Stack);
sei T der Zustand oben auf dem Stack;
push(A);
push(Sprungtabelle[T][A]);
end;
acc : acc := true;
kein Eintrag : Fehler;
end; { of case }
end
Aufstellen einer Syntaxanalysetabelle
- LR(0)-Elemente (S.17-18) obengenannten Scripts)
- Hüllenoperator CLOSURE (S.18-20)
- Sprungoperation GOTO (S.20-21
- Aufstellen des Zustandsgraphen (S.21-22)
- Erstellen der Syntaxanalysetabelle (S.23-25)
LR(0)-Elemente
Eine Produktion A → w mit einem Punkt irgendwo in der rechten Seite heißt LR(0)-Element.
Beispiel: zu A → bAa gibt es die LR(0)-Elemente: A → .bAa, A → b.Aa,
A → bA.a, A → bAa. .
Hülle - CLOSURE
Pseudocode nach: Drachenbuch S.295, Compilerbau Dr.Hellwig Geisse WS03, S.19
Hülle(I)
{
repeat
for ( jedes Element A → α.Bβ in I)
for ( jede Produktion B → γ )
I := I ∪ { B → .γ }
until (I hat sich in dieser Iteration nicht geändert);
return I;
}
Sprung - GOTO
Pseudocode nach: Drachenbuch S.297, Compilerbau Dr.Hellwig Geisse WS03, S.19
Sprung(I,X)
{
J := {};
for ( jedes Element A → α.Xβ in I)
J := J ∪ { A → αX.β }
return Hülle(J);
}
Tabellenkonstruktion
Pseudocode nach Compilerbau, Michael Jäger, S.107
Z := { Hülle( { S' → .S$} ) }; // Z Menge der Zustände des DEA, jeder Zustand wird durch Menge von LR(0)-Elementen charakterisiert
K := {}; // Menge der Transitionen
repeat
for (jeden Zustand I in Z)
for (jedes Element A → u.Xv in I)
begin
J := GOTO(I,X);
Z := Z ∪ {J}
K := K ∪ { (I,X) → J }
end;
until Z und K haben sich in der letzten Iteration nicht geändert
Ausnahme: Für $ wird kein Sprung berechnet; jeder Zustand mit S' → S.$ akzeptiert bei Vorausschau $.
Aus der Zustandsübergangstabelle ergeben sich zunächst die Shift-Aktionen und die Sprungtabelle.
Berechnung der Reduktionsaktionen R
R := {};
for (jeden Zustand I in Z)
for (jedes Element A → w. in I)
R := R ∪ { (I,A → w) };
Die Reduktionen werden nun in die Aktionstabelle eingetragen. Beim LR(0)-Verfahren wird unabhängig vom nächsten terminalen Zeichen reduziert. Hier steht also immer eine ganze Zeile voll die gleiche Reduktion. Anders beim SLR(1)-Verfahren: Aufgrund der Follow-Mengen kann entschieden werden, ob die Reduktion überhaupt möglich ist. Nur in den entsprechenden Spalten erfolgt der Eintrag. Auf diese Weise werden viele Shift-Reduce- bzw. Reduce-Reduce-Konflikte gelöst.
Links
Ausführlich kommentierter Weg zur Syntaxanalyse-Tabelle
Zur Grammatik
S-->T*S S-->T T-->i
soll ausführlich der Weg zur Syntaxanalyse-Tabelle besprochen werden.
Terminale Symbole: *,i
Nonterminale Symbole: S,T
Eine Produktion mit einem Punkt irgendwo in der rechten Seite heißt LR(0)-Element. Ein LR(0)-Element zeigt an, wo man bei der Bearbeitung einer Produktion gerade steht (Punkt=Standpunkt). Es ist klar, dass man mit .S beginnen wird, man steht so vor dem Start einer Ableitung. S könnte im vorliegenden Fall durch T*S oder T ersetzt werden, dh. der Anfangszustand wird bisher durch S'→.S, S→.T*S und S→.T beschrieben. Nachdem aber auch T durch i ersetzt werden könnte, wird er auf {S'→.S , S→.T*S , S→.T , T→.i} (.i*S geht nicht, da i*S keine rechte Seite einer Produktion) erweitert. Die beschriebenen Erweiterungen nennt man Hüllenbildung oder CLOSURE. Die Menge von LR(0)-Elementen wird mit einem Zustand, hier dem Anfangszustand, gleichgesetzt.
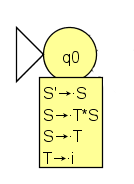
So könnte man also starten! Wie könnte es weitergehen?
Man sieht, dass man Produktionen mit S oder T auf der linken Seite oder auch das Terminal i verarbeiten könnte. Für diese drei Möglichkeiten werden mögliche Folgezustände, die GOTO-Mengen bestimmt. GOTO(q0,S) = q1 bestimmt dann die Menge von LR(0)-Elementen, die den Fortgang einer Ableitung beschreiben unter der Voraussetzung, dass das nonterminale Symbol S verwendet werden soll. Da in q0 das einzige Element mit S nach dem Punkt S'→.S ist, kann nur das Element S'→S. folgen. In diesem Element steht der Punkt ganz rechts, dh. eine komplette Produktion wurde durchgegangen. Der Zustand q1 wird deshalb als 'final' gekennzeichnet. Hier wird später reduziert (rechte Seite einer Produktion wird durch die linke ersetzt) werden können. Übrigens ohne Konflikt, da nur eine Möglichkeit besteht. GOTO(q0,T) = q2 ist etwas interessanter, hier gibt es zwei Möglichkeiten: S→T. oder S→T.*S . Die erste Möglichkeit wäre wieder final, da die ganze Produktion S→T abgearbeitet ist. Die zweite Möglichkeit bedeutet, dass man in der Abarbeitung von S→T*S mit dem terminalen Symbol * fortfahren könnte. Hier muss später eine reduce-shift (shift - erst mal auf den Stack schieben) - Entscheidung gefällt werden. GOTO(q0,i) = q3 gibt ausgehend von T→.i die weitere Abarbeitung an. Hier findet man nur das Element T→i. , dh. der Zustand ist final.
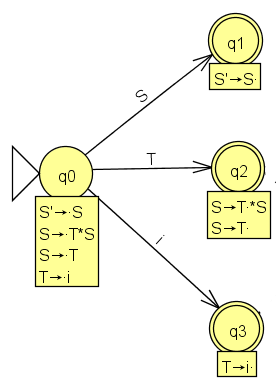
Die Zustände q1 und q3 lassen sich im Sinne des Erkennens einer Produktion nicht fortsetzen, q2 hingegen schon. Hier ist GOTO(q2,*) = q4 zu bestimmen. Natürlich ist S→T*.S in der Menge. Man könnte aber das S hinter dem Punkt als Anfang einer neuen Abarbeitung einer Produktion auffassen. In der Hüllenbildung werden daher die Elemente S→.T und S→.T*S hinzugenommen. Da man T aber wieder als Anfang einer Produktion haben kann, kommt noch T→.i hinzu.
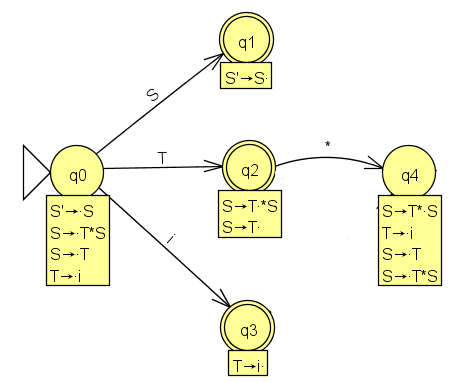
Beim Durchmustern der Elemente von q4 sieht man, dass S, T oder i als Grammatiksymbole folgen könnten. GOTO(q4,S) = q5 besteht nur aus S→T*S. und ist final (später Reduzierung ohne Konflikt). GOTO(q4,T) wird exakt als q2 erkannt. GOTO(q4,i) enthält nur das Element T→i. , das ist der schon aufgestellte Zustand q3. Der Zustandsgraph ist nun komplett. Er enthält in gewisser Weise alle Zustände, in die man im Verlauf einer Ableitung geraten könnte.
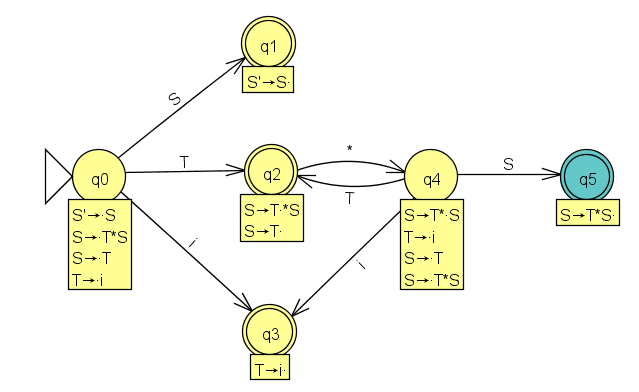
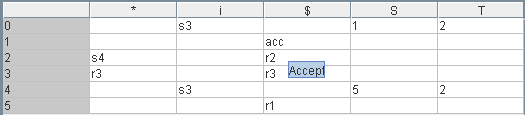
Um die Syntaxanalyse-Tabelle aufstellen zu können, schaut man sich zunächst die Transitionen des Zustandsgraphen an. Man findet drei Kanten, die mit terminalen Symbolen beschriftet sind. Sie führen zu den Einträgen [2,*]=s4, [0,i]=s3 und [4,i]=s3.
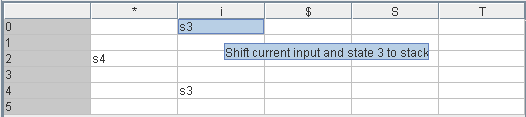
Der Eintrag [2,*]=s4 muss noch abgeklärt werden, denn q2 ist ein finaler Zustand, dh. die Abarbeitung einer Produktion wurde erkannt. Es liegt hier ein shift-reduce-Konflikt vor.
Die Transitionen mit nonterminalen Symbolen führen zu Einträgen in der 'Sprungtabelle': [0,S]=1, [0,T]=2, [4,T]=2 und [4,S]=5
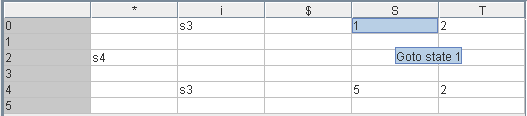
Reduktionen können nur in finalen Zuständen stattfinden. Um sie bequemer eintragen zu können, werden die Produktionen durchnummeriert, wobei die zusätzliche Produktion S'→S (dazu später mehr) die Nummer 0 bekommt. Zustand 1 führt dann eigentlich zum Eintrag r0 in der kompletten Zeile 0. Beim LR(0)-Verfahren wird das wirklich gemacht, beim SLR-Verfahren schaut man sich die Menge FOLLOW(S')=FOLLOW(S)={$} an, die angibt, welche terminale Zeichen überhaupt auf S' folgen können. In unserem Fall ist das nur das Eingabeende- Zeichen $. Also lautet der Eintrag [1,$]=r0. Der Rest der Zeile bleibt frei. Gewöhnlich schreibt man aber nicht r0, sondern acc (accept), denn die Reduzierung S'←S zeigt an, dass der Ableitungsbaum erfolgreich rückwärts aufgebaut wurde. Zustand 2 kann zur Reduktion r2 (S←T) führen, jedoch nur, wenn das folgende Zeichen in FOLLOW(S)={$} enthalten ist. Damit ist der shift-reduce-Konflikt in [2,*] gelöst. Zustand 3 führt zur Reduktion T←i (r3). FOLLOW(T)={*,$} bedeutet, dass nur die Zeichen * oder $ folgen können, daher gibt es nur Einträge in den entsprechenen Spalten. Zustand 5 führt zur Reduktion r1, wegen FOLLOW(S)={$} ergibt sich [5,$]=r1. Alle Felder in der Tabelle, die noch nicht besetzt sind, zeigen später einen Fehler bei der Abarbeitung an, dh. die Eingabe wird nicht akzeptiert.
Man sieht, wie nützlich die FOLLOW-Mengen sind. Aber wozu braucht man im SLR-Verfahren die FIRST-Mengen? Antwort: Bei der Bestimmung der FOLLOW-Mengen, denn für eine Produktion A → αBβ gehört FIRST(β) zu FOLLOW(B) hinzu.
Was soll die hinzufügte 0-te Produktion S'→S? Vermutung: Auch bei mehreren Startsymbolen gibt das Erreichen von S' eindeutig das Ende des Parsevorgangs an. Das hätte man auch mit einer Überprüfung auf Startzustand erreichen können. Wahrscheinlich ist es so einfacher.
![]()