| |
|||
| HSG |
|
Bezeichner in Python
In der Python Language Reference wird die Syntax der Sprache beschrieben. Bezeichner (identifier) werden dabei folgendermaßen beschrieben:
identifier ::= id_start id_continue* id_start ::= <all characters in general categories Lu, Ll, Lt, Lm, Lo, Nl, the underscore, and characters with the Other_ID_Start property> id_continue ::= <all characters in id_start, plus characters in the categories Mn, Mc, Nd, Pc and others with the Other_ID_Continue property>
Vereinfacht gesagt, muss ein Bezeichner mit einem Buchstaben oder Unterstrich beginnen. Optional dürfen Buchstaben, Unterstrich oder Ziffern folgen.
>>> ö = 3 >>> ö 3 >>> € = 5 SyntaxError: invalid character in identifier >>> 1b = 7 SyntaxError: invalid syntax >>> b1 = 7
Wenn b für einen Buchstaben oder Unterstrich und z für eine Ziffer steht, so kann man leicht einen Akzeptor für einen Bezeichner angeben:
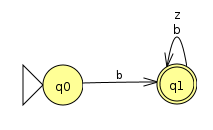
Dabei gilt die übliche Konvention, dass der Fehlerzustand nicht explizit angegeben wird.
Python-Realisierung
Es typisch, dass bei der Realisierung eines abstrakten Automaten Zeichen erst Zeichenklassen zugeordnet werden müssen. Das kann z.B. über Mengen geschehen.
class Bezeichner(object):
def __init__(self):
self.zustaende = ('q0','q1','f')
self.eingaben = ('b','z','s') # Buchstabe, Ziffer, sonst
self.startzustand = 0
self.endzustaende = set([1])
self.f = ((1,2,2),
(1,1,2),
(2,2,2))
self.zustand = self.startzustand
def ein(self,ch):
ABC = set(chr(n) for n in range(ord('A'),ord('Z')+1) ) # ABC = {'A',..,'Z'}
abc = set(chr(n) for n in range(ord('a'),ord('z')+1) ) # abc = {'a',..,'z'}
Z = set(chr(n) for n in range(ord('0'),ord('9')+1) ) # Z = {'0',..,'9'}
B = ABC|abc|{'_'} # | bedeutet 'vereinigt'
if ch in B:
eingabe = self.eingaben.index('b') # ch wird als b verarbeitet
elif ch in Z:
eingabe = self.eingaben.index('z') # ch wird als z verarbeitet
else:
eingabe = self.eingaben.index('s') # ch wird als s verarbeitet
# print(self.zustand, eingabe) # DEBUG
self.zustand = self.f[self.zustand][eingabe]
def akzeptiert(self,s):
"""
gibt genau dann True zurück, wenn der Automat nach Abarbeitung des Strings s
in einem Endzustand ist
"""
self.zustand = self.startzustand
for ch in s:
self.ein(ch)
return self.zustand in self.endzustaende
Der Akzeptor wird getestet.
>>> b = Bezeichner()
>>> b.akzeptiert('a2')
True
>>> b.akzeptiert('2')
False
>>> b.akzeptiert('_2')
True
Fließkomma-Zahlen
Folgende Grammatik beschreibt eine Python-Fließkomma-Zahl floatnumber.
floatnumber ::= pointfloat | exponentfloat
pointfloat ::= [intpart] fraction | intpart "."
exponentfloat ::= (intpart | pointfloat) exponent
intpart ::= digit+
fraction ::= "." digit+
exponent ::= ("e" | "E") ["+" | "-"] digit+
digit ::= "0"..."9"
Akzeptor für pointfloat
In einer ersten Stufe wird mit JFlap systematisch der Automat aufgestellt.
NEA

DEA

DEA, minimiert

Python-Quelltext
class Pointfloat(object):
def __init__(self):
self.zustaende = ('q0','q1','q2','q3','f')
self.eingaben = ('z','p','s') # Ziffer, Punkt, sonst
self.endzustaende = set([3])
self.f = ((2,1,4),
(3,4,4),
(2,3,4),
(3,4,4),
(4,4,4))
self.zustand = 0
def ein(self,ch):
Z = set(chr(n) for n in range(ord('0'),ord('9')+1) )
if ch in Z:
eingabe = self.eingaben.index('z') # ch wird als z verarbeitet
elif ch == '.':
eingabe = self.eingaben.index('p') # ch wird als p verarbeitet
else:
eingabe = self.eingaben.index('s') # ch wird als s verarbeitet
# print(self.zustand, eingabe) # DEBUG
self.zustand = self.f[self.zustand][eingabe]
def akzeptiert(self,s):
"""
gibt genau dann True zurück, wenn der Automat nach Abarbeitung des Strings s
in einem Endzustand ist
"""
self.zustand = 0
for ch in s:
self.ein(ch)
return self.zustand in self.endzustaende
Tests
>>> p = Pointfloat()
>>> p.akzeptiert('1.23')
True
>>> p.akzeptiert('.23')
True
>>> p.akzeptiert('1.')
True
>>> p.akzeptiert('12')
False
>>> p.akzeptiert('1.2.3')
False
Aufgabe
Entwickle systematisch einen Akzeptor für floatnumber.
Einfacher Scanner
Wir nehmen als eine einfache Sprache L durch Whitespaces getrennte Bezeichner und pointfloats an. Ein Scanner soll nun aus einer Zeichenkette die Tokens Bezeichner und pointfloat extrahieren bzw. einen Fehler anzeigen, wenn dies nicht mehr möglich ist. Sicher werden die bereits erstellten Automaten nützlich sein. Trotzdem ist die Aufgabe insofern anders als eine Zeichenkette, die z.B. als Bezeichner erkannt wurde, gespeichert werden soll. Außerdem soll der Scanner nach Erkennen eines Tokens weiterarbeiten.
NEA

DEA
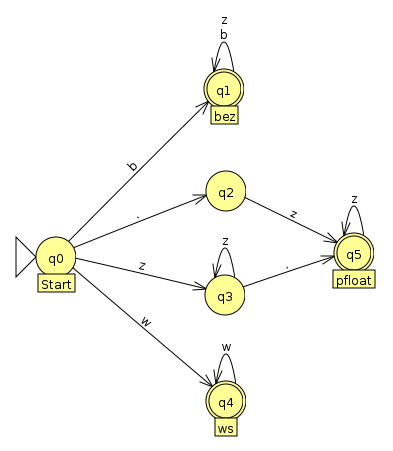
spezieller DEA

Der letzte Automat arbeitet nun so: Ein Puffer nimmt die verarbeiteten Zeichen auf. Sobald einer der Endzustände über eine Transition mit Stern verlassen wird, wird ein Token bestehend aus Endzustand und Puffer gespeichert. Dabei gehört das Zeichen, das zum Verlassen geführt hat, nicht mehr zum Puffer. Dieses Zeichen wird vielmehr für einen neuen Start aus dem Startzustand benutzt. Gerät man in den Fehlerzustand, so wird ein Fehler-Token gespeichert. Ist man nach dem letzten Zeichen in einem Endzustand, so wird das entsprechende Token gespeichert, sonst ein Unerwartetes-Ende-Token.
class Scanner(object):
def __init__(self):
self.zustaende = ('q0','q1','q2','q3','q4','q5','f')
self.eingaben = ('b','z','p','w','s') # Buchstabe, Ziffer, Punkt, Whitespace, sonst
self.endzustaende = set([1,4,5])
self.f = ((1,3,2,4,6),
(1,1,0,0,6),
(6,5,6,6,6),
(6,3,5,6,6),
(0,0,0,4,6),
(0,5,0,0,6),
(6,6,6,6,6))
self.zustand = 0
self.puffer = ''
self.tokenliste = []
self.abbruch = False
def ein(self,ch):
ABC = set(chr(n) for n in range(ord('A'),ord('Z')+1) )
abc = set(chr(n) for n in range(ord('a'),ord('z')+1) )
Z = set(chr(n) for n in range(ord('0'),ord('9')+1) )
W = {'\n','\t',' '}
B = ABC|abc|{'_'} # | bedeutet 'vereinigt'
if ch in B:
eingabe = self.eingaben.index('b') # ch wird als b verarbeitet
elif ch in Z:
eingabe = self.eingaben.index('z') # ch wird als z verarbeitet
elif ch == '.':
eingabe = self.eingaben.index('p') # ch wird als p verarbeitet
elif ch in W:
eingabe = self.eingaben.index('w') # ch wird als w verarbeitet
else:
eingabe = self.eingaben.index('s') # ch wird als s verarbeitet
self.puffer = self.puffer + ch
alterzustand = self.zustand
self.zustand = self.f[self.zustand][eingabe]
if (alterzustand in self.endzustaende) and (self.zustand == 0):
if alterzustand == 1:
self.tokenliste.append(('Bezeichner',self.puffer[:-1]))
elif alterzustand == 5:
self.tokenliste.append(('pointfloat',self.puffer[:-1]))
elif alterzustand == 4:
pass
else:
self.tokenliste.append(('unerwarteterFehler',self.puffer[:]))
ch = self.puffer[-1]
self.puffer = ''
self.ein(ch)
if self.zustand == 6:
self.tokenliste.append(('ScanFehler',self.puffer[:]))
self.abbruch = True
def scan(self,s):
"""
gibt zu dem Strings s eine Tokenliste zurück
"""
self.zustand = 0
self.abbruch = False
self.puffer = ''
self.tokenliste = []
for ch in s:
if not self.abbruch:
self.ein(ch)
if self.zustand in self.endzustaende:
if self.zustand == 1:
self.tokenliste.append(('Bezeichner',self.puffer[:]))
elif self.zustand == 5:
self.tokenliste.append(('pointfloat',self.puffer[:]))
else:
if not self.abbruch:
self.tokenliste.append(('UnerwartetesEnde',self.puffer[:]))
return self.tokenliste
Tests
>>> s = Scanner()
>>> s.scan('a23 12.34xxx\n\n\t')
[('Bezeichner', 'a23'), ('pointfloat', '12.34'), ('Bezeichner', 'xxx')]
>>> s.scan('a23 12,34xxx\n\n\t')
[('Bezeichner', 'a23'), ('ScanFehler', '12,')]
>>> s.scan('a23 12.34xxx\n\n\t9')
[('Bezeichner', 'a23'), ('pointfloat', '12.34'), ('Bezeichner', 'xxx'), ('UnerwartetesEnde', '9')]
>>> s.scan('a23 12.34xxx\n\n\t9.')
[('Bezeichner', 'a23'), ('pointfloat', '12.34'), ('Bezeichner', 'xxx'), ('pointfloat', '9.')]
>>>
Aufgabe
Erweitere bzw. modifiziere obigen Scanner so, dass Whitespaces als Token ausgegeben werden und dass ein neues Token 'zuw' mit der Zeichenfolge ':=' erkannt wird.
Links
- Lexikalischer Scanner - wikipedia
- Lex - wikipedia