| |
|||
| HSG |
|
Der 'neue' Bonsai-Compiler
Der Compiler benötigt das Modul PLY. Will man den Namen der Quelltextdatei nicht direkt in den Quelltext schreiben, so ist der normale Aufruf:
python3 py2bon.py add0.py
Aus der Datei 'add0.py'
from goto import goto, label
a = 12
b = 33
label .SB
if b > 0:
goto .SK
else:
goto .SE
label .SK
b = b - 1
a = a + 1
goto .SB # Achtung, wird leicht vergessen
label .SE
print(a,b)
wird die Datei 'add0.bon'.
tst2 jmp4 jmp7 dec2 inc1 jmp1 hlt # 12 # 33 ; a = 12 ; b = 33
Beispieldateien: add0.py, divmod.py, sumn.py
Definition der Sprache 'goto-Python'
Verwendet wird die Syntax der Webseite Generation of Syntax Diagrams.
bon = (befehl bon)? befehl = inc|dec|jmp|tst|zuw|lab inc = 'ID' '=' 'ID' '+' 'NUMBER' dec = 'ID' '=' 'ID' '-' 'NUMBER' jmp = 'goto' 'LID' tst = 'if' 'ID' '>' 'NUMBER' ':' 'goto' 'LID' 'else' ':' 'goto' 'LID' zuw = 'ID' '=' 'NUMBER' lab = 'label' 'LID'
erzeugt folgende Syntaxdiagramme:
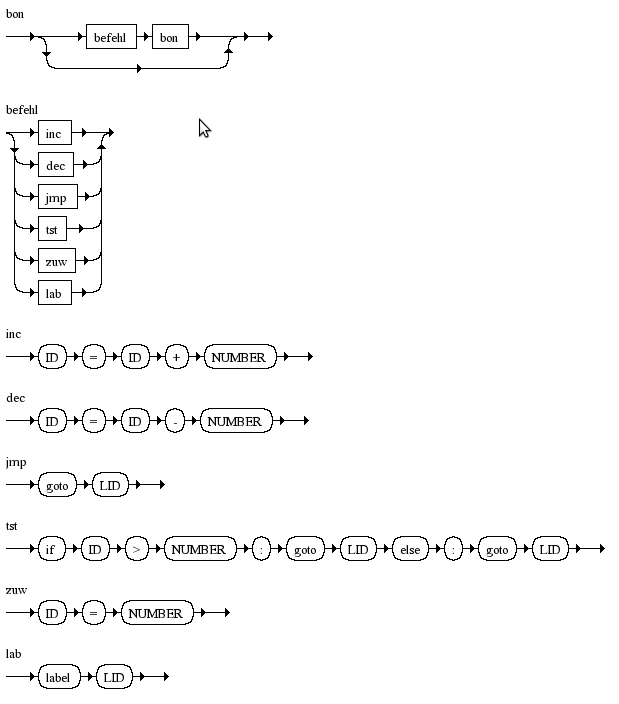
Zusätzlich zur Grammatik ist im Parser festgelegt, dass im inc- und dec-Befehl der erste und zweite Bezeichner ID gleich sein muss und dass die Zahl NUMBER gleich 1 sein muss. Ebenso überwacht der Parser, dass im tst-Befehl die Zahl NUMBER gleich 0 ist.
Die Token ID, LID, NUMBER, FROMZEILE, PRINTZEILE und KOMMENTAR sind folgendermaßen festgelegt:
ID = ⸢[a-zA-Z_][a-zA-Z_0-9]*⸥ LID = ⸢\.[a-zA-Z_][a-zA-Z_0-9]*⸥ NUMBER = ⸢\d+⸥ FROMZEILE = ⸢from.*⸥ PRINTZEILE = ⸢print.*⸥ KOMMENTAR = ⸢\#.*⸥
Die Token FROMZEILE, PRINTZEILE und KOMMENTAR werden ignoriert.
Quelltext des Compilers
import ply.lex as lex
reserved = {'label' : 'LABEL',
'if' : 'IF',
'goto' : 'GOTO',
'else' : 'ELSE' }
tokens = ['ID','LID','NUMBER','FROMZEILE',
'PRINTZEILE','KOMMENTAR'] + list(reserved.values())
literals = '=:>-+'
t_LID = r'\.[a-zA-Z_][a-zA-Z_0-9]*'
def t_FROMZEILE(t):
r'from.*'
def t_PRINTZEILE(t):
r'print.*'
def t_KOMMENTAR(t):
r'\#.*'
def t_ID(t):
r'[a-zA-Z_][a-zA-Z_0-9]*'
t.type = reserved.get(t.value,'ID') # get gibt Wert aus Dictionary zurück,
return t # wenn nicht gefunden 'ID'
def t_NUMBER(t):
r'\d+'
t.value = int(t.value)
return t
def t_newline(t):
r'\n+'
t.lexer.lineno = t.lexer.lineno + len(t.value)
t_ignore = ' \t'
def t_error(t):
print('Unerwartetes Zeichen:',t.value[0],',Zeile:',s.lineno)
t.lexer.skip(1)
s = lex.lex()
import ply.yacc as yacc
n = 1 # Zeilennummer der Ausgabe
nv = 1 # Variablennummer
sym = {} # Symboltabelle, Dictionary
var = [] # Liste der Anfangs-Variablen mit Werten
lab = [] # Liste der Labels
lauf1 = '' # String für 1.Lauf
def p_0(p):
'bon : befehl bon'
def p_1(p):
'bon :'
def p_2(p):
'befehl : inc'
def p_3(p):
'befehl : dec'
def p_4(p):
'befehl : jmp'
def p_5(p):
'befehl : tst'
def p_6(p):
'befehl : zuw'
def p_7(p):
'befehl : lab'
def p_8(p):
"inc : ID '=' ID '+' NUMBER"
if (p[1] != p[3]) or (p[5] != 1):
print('Syntaxfehler in inc, Zeile:',s.lineno)
raise SyntaxError
global lauf1,n
lauf1 = lauf1+'inc '+p[1]+'\n'
n = n+1
def p_9(p):
"dec : ID '=' ID '-' NUMBER"
if (p[1] != p[3]) or (p[5] != 1):
print('Syntaxfehler in dec, Zeile:',s.lineno)
raise SyntaxError
global lauf1,n
lauf1 = lauf1+'dec '+p[1]+'\n'
n = n+1
def p_10(p):
"jmp : GOTO LID"
global lauf1,n
lauf1 = lauf1+'jmp '+p[2]+'\n'
n = n+1
def p_11(p):
"tst : IF ID '>' NUMBER ':' GOTO LID ELSE ':' GOTO LID"
if (p[4] != 0):
print('Syntaxfehler in tst, Zeile:',s.lineno)
raise SyntaxError
global lauf1,n
lauf1 = lauf1+'tst '+p[2]+'\n'
lauf1 = lauf1+'jmp '+p[7]+'\n'
lauf1 = lauf1+'jmp '+p[11]+'\n'
n = n+3
def p_12(p):
"zuw : ID '=' NUMBER"
global var,sym,nv
sym.update({p[1]:nv})
var.append((p[1],p[3]))
nv = nv + 1
def p_13(p):
'lab : LABEL LID'
global lab,sym
lab.append((p[2],n))
sym.update({p[2]:n})
def p_error(p):
print('Syntaxfehler in Zeile:',s.lineno)
pr = yacc.yacc()
import sys
try:
dateiname = sys.argv[1]
except:
dateiname = 'sumn.py'
datei = open(dateiname,'r')
inhalt = datei.read()
datei.close()
pr.parse(inhalt)
# Symboltabelle einarbeiten und Ausgabedatei erzeugen
zeilen = lauf1.split('\n')
zeilen.remove('')
ausgabename = dateiname.split('.')[0]+'.bon'
datei = open(ausgabename,'w')
for z in zeilen:
zalt = z.split(' ')
zneu = zalt[0]+str(sym.get(zalt[1]))+'\r\n'
datei.write(zneu)
datei.write('hlt\r\n')
for v in var:
zneu = '# '+str(v[1])+'\r\n'
datei.write(zneu)
for v in var:
zneu = '; '+str(v[0])+' = '+str(v[1])+'\r\n'
datei.write(zneu)
datei.close()
datei = open(ausgabename,'r') # DEBUG
inhalt = datei.read() # DEBUG
datei.close() # DEBUG
print(inhalt) # DEBUG
Compiler in Aktion
Wer den Compiler in Aktion sehen will, kann die mit ausführlichen DEBUG-Informationen versehene Version py2bonDEBUG.py benutzen.
Folgende Ausgabe wird bei der Verarbeitung obiger Datei 'add0.py' erzeugt.
>>>
WARNING: Token 'PRINTZEILE' defined, but not used
WARNING: Token 'FROMZEILE' defined, but not used
WARNING: Token 'KOMMENTAR' defined, but not used
WARNING: There are 3 unused tokens
Generating LALR tables
LexToken(FROMZEILE,'from goto import goto, label',1,0)
LexToken(ID,'a',3,30)
LexToken(ISTGLEICH,'=',3,32)
LexToken(NUMBER,'12',3,34)
LexToken(ID,'b',4,37)
zuw: a = 12
Symboltabelle: {'a': 1}
Variablentabelle: [('a', 12)]
befehl : zuw
LexToken(ISTGLEICH,'=',4,39)
LexToken(NUMBER,'33',4,41)
LexToken(LABEL,'label',6,45)
zuw: b = 33
Symboltabelle: {'a': 1, 'b': 2}
Variablentabelle: [('a', 12), ('b', 33)]
befehl : zuw
LexToken(LID,'.SB',6,51)
LexToken(IF,'if',7,55)
lab: label .SB
Labeltabelle: [('.SB', 1)]
Symboltabelle: {'a': 1, '.SB': 1, 'b': 2}
befehl : lab
LexToken(ID,'b',7,58)
LexToken(GROESSER,'>',7,60)
LexToken(NUMBER,'0',7,62)
LexToken(DOPPELPUNKT,':',7,63)
LexToken(GOTO,'goto',8,69)
LexToken(LID,'.SK',8,74)
LexToken(ELSE,'else',9,78)
LexToken(DOPPELPUNKT,':',9,82)
LexToken(GOTO,'goto',10,88)
LexToken(LID,'.SE',10,93)
LexToken(LABEL,'label',12,98)
tst : if b > 0 : goto .SK else : goto .SE
lauf1:
tst b
jmp .SK
jmp .SE
befehl : tst
LexToken(LID,'.SK',12,104)
LexToken(ID,'b',13,108)
lab: label .SK
Labeltabelle: [('.SB', 1), ('.SK', 4)]
Symboltabelle: {'a': 1, '.SB': 1, 'b': 2, '.SK': 4}
befehl : lab
LexToken(ISTGLEICH,'=',13,110)
LexToken(ID,'b',13,112)
LexToken(MINUS,'-',13,114)
LexToken(NUMBER,'1',13,116)
LexToken(ID,'a',14,118)
dec : b = b - 1
lauf1:
tst b
jmp .SK
jmp .SE
dec b
befehl : dec
LexToken(ISTGLEICH,'=',14,120)
LexToken(ID,'a',14,122)
LexToken(PLUS,'+',14,124)
LexToken(NUMBER,'1',14,126)
LexToken(GOTO,'goto',15,128)
inc : a = a + 1
lauf1:
tst b
jmp .SK
jmp .SE
dec b
inc a
befehl : inc
LexToken(LID,'.SB',15,133)
LexToken(KOMMENTAR,'# Achtung, wird leicht vergessen',15,156)
LexToken(LABEL,'label',17,190)
jmp : goto .SB
lauf1:
tst b
jmp .SK
jmp .SE
dec b
inc a
jmp .SB
befehl : jmp
LexToken(LID,'.SE',17,196)
LexToken(PRINTZEILE,'print(a,b)',19,201)
lab: label .SE
Labeltabelle: [('.SB', 1), ('.SK', 4), ('.SE', 7)]
Symboltabelle: {'a': 1, '.SB': 1, 'b': 2, '.SK': 4, '.SE': 7}
befehl : lab
bon :
bon : befehl bon
bon : befehl bon
bon : befehl bon
bon : befehl bon
bon : befehl bon
bon : befehl bon
bon : befehl bon
bon : befehl bon
bon : befehl bon
erzeugte Datei:
tst2
jmp4
jmp7
dec2
inc1
jmp1
hlt
# 12
# 33
; a = 12
; b = 33
>>>