| |
|||
| HSG |
|
Experimente auf der Python-Shell
Es gibt in Python keinen eigenen Datentyp für Zeichen. Ein Zeichen ist in Python ein String der Länge 1, z.B. ch1 = 'A' oder ch2 = 'ü' oder auch ch3 = '€'.
>>> ch1 = 'A' >>> ch2 = 'ü' >>> ch3 = '€' # AltGr + E >>> len(ch3) 1 >>> len(ch2) 1 >>> len(ch1) 1 >>> type(ch1) <class 'str'> >>>
Eine direkte Typumwandlung in eine ganze Zahl schlägt fehl:
>>> n1 = int(ch1)
Traceback (most recent call last):
File "<pyshell#8>", line 1, in <module>
n1 = int(ch1)
ValueError: invalid literal for int() with base 10: 'A'
Trotzdem ist jedem Zeichen ch (Zeichen = character, engl.) eine Nummer zugeordnet. Diese Nummer erhält man mit der eingebauten Funktion ord.
>>> ord(ch1)
65
>>> ord('B')
66
>>> ord(ch2)
252
>>> ord(ch3)
8364
>>>
Diese Nummer (Typ int) kann man in verschiedenen Zahlsystemen darstellen.
>>> bin(65) '0b1000001' >>> hex(65) '0x41' >>> bin(8364) '0b10000010101100' >>> hex(8364) '0x20ac' >>>
ord hat die Umkehrfunktion chr. chr(n) ist also das Zeichen mit der Nummer n.
>>> n = int('260E',16)
>>> n
9742
>>> chr(n)
'☎'
>>> chr(65)
'A'
>>>
Das �-Problem
Unicode
Informiere dich in dem wikipedia-Artikel über Unicode.
- Wieviele Zeichen sind zur Zeit etwa in Unicode dargestellt?
- Wo findet man eine (link fehlt) über die Unicode-Zeichen? Welche Unicode-Codierung hat das Euro-Zeichen?
- Stellen die Browser alle Unicode-Zeichen dar?
Unicode unter Python
Seit Python 3 werden Unicode-Zeichen als einzelnes Zeichen behandelt unabhängig von der Unicode-Nummer. Erst bei der Umwandlung eines Strings in Bytes muss eine Codierung angegeben werden. Im Unicode-Block 'Verschiedene mathematische Symbole-B' findet man z.B. den Eintrag 'U+29BF (10687) ⦿ Eingekreistes Aufzählungszeichen CIRCLED BULLET'. Ein beliebiges Unicode-Zeichen lässt sich in Python über \uhhhh eingeben. Dabei steht hhhh für 4 hexadezimale Ziffern
>>> s = 'aBc\u29bfdE' >>> s 'aBc⦿dE' >>> s ='\u0041_B' >>> s 'A_B'
Sonderzeichen unter Linux
Unter Linux kann mit mit AltGr und AltGr+Shift die 3. und 4. Tastaturebene erreichen. Teste auch, ob im verwendeten Programm Strg+Shift+u ein kleines unterstrichenes u erzeugt. Falls ja, kann man wie in Python hexadezimale Ziffern eingeben, um ein bestimmtes Unicode-Zeichen zu erhalten.
Codierungen
Das Unicode-System gibt jedem Zeichen eine Nummer. Diese Nummer muss aber auf Datei- oder Speicherebene durch Bytes ausgedrückt werden. Eine naheliegende Idee ist es, die Nummer einfach binär darzustellen.
ASCII
Mit Hilfe des wikipedia-Artikels über ASCII sollen folgende Fragen beantwortet bzw. Aufgaben bearbeitet werden:
- Was bedeutet ASCII?
- Wieviele Bit benutzt ASCII?
- Gib drei Beispiele für Steuerzeichen an.
- Gib die ASCII-Codierung für 'A', 'b' und 'Ö' binär, hexadezimal und dezimal an.
- Welche Nachteile hat ASCII? Welche Vorteile hat ASCII?
Folgerung
Manche ältere Protokolle wie z.B. ftp basieren auf 7-bit-ASCII. Welches Problem ergibt sich z.B. beim Übertragen einer Datei mit Namen 'böse.txt'?
ISO 8859
Informiere dich in dem wikipedia-Artikel über ISO 8859.
- Was bedeutet ISO?
- Wieviele Bit benutzt ISO 8859?
- Wie gibt man unter Windows das Zeichen mit der Codierung 254 ein, siehe unter Eingabe französischer Sonderzeichen auf einer Windows-Tastatur
Codepage 437 und Codepage Windows-1252
Informiere dich in den wikipedia-Artikeln über Codepage 437 und Codepage 1252.
- Welchen Code hat das Zeichen ╠ in den beiden Codierungen?
Experimente mit einer Codierung
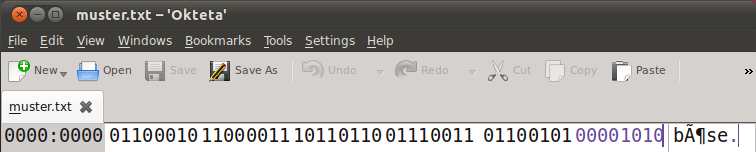
Erstelle mit einem Editor eine Textdatei z.B. 'muster.txt', die das Wort 'böse' enthält. Speichere die Datei unter der Codierung utf8 ab (geschieht unter Linux vermutlich automatisch) und lade die Datei in einen Browser. Was beobachtest du? Teste unter Ansicht/Zeichenkodierung (firefox) verschiedene Codierungen? Verwende einen Hex-Editor, z.B. Okteta, um die 'rohen' Bytes der Datei muster.txt zu sehen.
Was ist eigentlich die richtige Schreibung, 'Kodierung' oder 'Codierung'?
utf8
Zu dem 'ö' gehören die Bytes 1100 0011 1011 0110. Mit diesen zwei Bytes codiert utf8 das 'ö'. Wie funktioniert diese Codierung?
- ASCII-Zeichen werden direkt als ASCII also mit dem höchsten Bit 0 codiert.
- Beispiel: 0110 0010, Datenbits: 11000102 = 64+32+2 = 98, chr(98) = 'b'
- Alle anderen Zeichen werden in eine Folge von zwei bis vier Bytes codiert. Die Bytes eine Folge haben alle ein höchstes Bit 1. Das Startbyte beginnt mit 11.. , Folgebytes beginnen mit 10.. . Beim Startbyte gibt die Anzahl der Einsen am Anfang die Gesamtlänge der Bytefolge an. Die restlichen Bits stellen die Unicode-Nummer des Zeichens dar.
- Beispiel: 1100 0011 1011 0110, Datenbits: 000 1111 01102 = 246, chr(246) = 'ö'
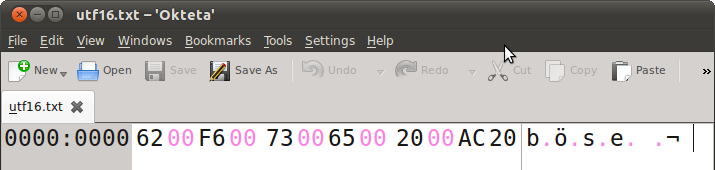
Experiment mit utf16
Erstelle z.B. mit dem Editor Kate eine Datei utf16.txt mit dem Inhalt 'böse €' und speichere unter der Codierung utf16 ab. Wie groß ist die Datei? Verwende einen Hex-Editor z.B. Okteta, um dir die 'rohen' Bytes anzusehen.
Fragen
- Welchen Nachteil hat die Codierung utf16?
- Welchen Vorteil hat die Codierung utf8?
- Wie ist in utf8 das Euro-Zeichen € codiert?
Aufgabe
Welches Zeichen stellt die utf-8 codierte Bytefolge
1110 1111 1011 1111 1011 1101
dar?
Python: chr(int('1111111111111101',2))
Replacement character
Replacement character - en.wikipedia.org/wiki
Byte-Order-Mark
Informiere dich in dem wikipedia-Artikel über die Byte-Order-Mark.
- Was wird wohl passieren, wenn man das Unicode-Zeichen zero width no-break space ausgibt?
- Wieso ist das Unicode-Zeichen U+FFFE nicht definiert?
- Was ist der Unterschied zwischen Little-Endian und Big-Endian?
- Benutze Suphex (oder einen anderen Hexeditor, um eine Datei bomtest.txt zu erzeugen, die mit dem BOM in utf8-Darstellung beginnt. Die Datei besteht zunächst aus drei Byte. Lade die Datei mit Notepad ein und füge die Sonderzeichen ÄÖÜ€ hinzu. Speichere die Datei und schaue sie nun wieder mit dem Hexeditor an. Wie sind die Sonderzeichen kodiert? Gib die Bytes an.
- Versuche, die utf8-Darstellung der Unicode-Codierung für ein Zeichen zu verstehen.
- Entferne mit einem Hexeditor die drei Byte des BOM und schaue die Datei mit wordpad an.
Rätsel
Mit einem E-Mail-Programm wurde folgende Mail empfangen. Was ist da wohl passiert?

Experiment
Schaue dir die Datei utf8.py mit dem Browser an. Ist mit der Darstellung alles in Ordnung?
Aufgaben
Information und Daten
Was ist der Unterschied zwischen Information und Daten?
Darstellung von Zeichen
- ASCII - wikipedia
- ISO 8859 - wikipedia
- Unicode - wikipedia
- Liste_der_Unicode-Blöcke - wikipedia
- UTF-8 - wikipedia
- Byte-Order-Mark - wikipedia

-
Delphi:
 utf8.zip
utf8.zip
-
Python:
 utf8gui.py
utf8gui.py
- Unicode - Unterstützung als Merkmal des weltweiten Austauschs von Dokumenten
- utf8-Zeichentabelle
- Link zu iso8859.php und utf8.php
- Alan Wood's Unicode Resources
- UniRed - Unicode Editor
- Notepad kann mit UTF8 umgehen! (utf8test.txt)
- EditPadLite - Editor, der nach utf-8 konvertieren kann