| |
|||
| HSG |
|
Warum Threads?
- Paralleles Rechnen
- Parallel ablaufende I/O-Vorgänge
- Asynchrone I/O-Ereignisse
Was sind Threads?
Moderne Betriebssysteme benutzen Timesharing-Verfahren, um verschiedene Programme scheinbar gleichzeitig auszuführen. Jedes laufende Programm ist dabei ein Prozess (Unix-Terminologie) bzw. Task (Windows-Terminologie). Prozesse bekommen reihum Rechenzeit. Ein typischer Wert könnte bei etwa 10 ms liegen. Nach Ablauf der Zeit löst ein Hardware-Timer einen Interrupt aus, der den Zustand des laufenden Prozesses speichert und ihn stoppt (sleep) und den Zustand des folgenden Prozesses restauriert und ihn startet. Das ist natürlich nur das Grundprinzip. Rechenzeit wird auch nach Prioritäten vergeben und die Rechendauer kann mal kürzer oder länger sein.
Threads unterscheiden sich von Prozessen dadurch, dass sie den gleichen globalen Speicherbereich wie der Mutterprozess benutzen. Über diesen Speicherbereich läuft die Kommunikation zwischen den Threads und zu dem Mutterprozess. Durch diese gemeinsame Nutzung kann es zu Konflikten kommen, die gelöst werden müssen.
Beispiel 1
Ein guter Start ist sicher die Original-Dokumentation 16.2. threading - Higher-level threading interface

>>> import threading
>>> import time
>>> def tuewas():
print('Hier bin ich, der Thread!')
time.sleep(10)
print('Meine Zeit als Thread ist abgelaufen.')
>>> threading.active_count()
1
>>> th = threading.Thread(target = tuewas)
>>> th.isAlive()
False
>>> th.start()
>>> Hier bin ich, der Thread!
3+4
7
th.isAlive()
True
threading.active_count()
2
>>> Meine Zeit als Thread ist abgelaufen.
>>> threading.active_count()
1
>>> th.isAlive()
False
>>>
Während der Thread lief, wurde im main-Thread 3+4 berechnet, nachgesehen, ob der Thread th noch lebt, und die Anzahl der aktiven Threads ausgegeben.
'Erniedriger gegen Erhöher' - das Problem
a = 0
def erhoehe():
global a
for i in range(100000):
a = a + 1
def erniedrige():
global a
for i in range(100000):
a = a - 1
erhoehe()
erniedrige()
print(a)
Das Beispielprogramm enthält noch keine Threads und soll nur das Prinzip zeigen. Kommt es für den letztendlichen Wert von a auf die Reihenfolge bei erhoehe() und erniedrige() an?
a = 0
def erhoehe():
global a
for i in range(100000):
a = a + 1
def erniedrige():
global a
for i in range(100000):
a = a - 1
import threading
erhoeher = threading.Thread(target = erhoehe)
erniedriger = threading.Thread(target = erniedrige)
erniedriger.start()
erhoeher.start()
print(a)
Jetzt werden Threads benutzt. Ein Programmlauf gab folgendes Ergebnis:
>>> -10683 >>> a -61012 >>> a -61012 >>>
Das Ergebnis überrascht. Ein weiterer Programmlauf ergibt:
>>> -21910 >>> a -30710 >>>
Zumindest die Veränderung der Variablen a nach 'Programmende' ist erklärlich. Die Threads arbeiten eventuell noch. Man könnte sicherheitshalber noch einige Zeit warten. Besser ist es, die Beendigung der Threads abzuwarten.
Ganz Experimentierfreudige werden die Anzahl der Zuweisungen vielleicht auf 1000 senken und dabei eine interessante Entdeckung machen. Welche Arbeitsweise unterstellen wir dem Scheduler? (Round Robin)
Weiter kann man durchaus auf die Idee kommen, einen Thread sein eigenes Ende durch eine print-Anweisung anzeigen zu lassen. Zumindest unter Idle, das ja eine laufende Tkinter-Anwendung ist, führt das zu Abstürzen und schwer erklärbaren Effekten. Hier kommen sich anscheinend einige Threads ins Gehege. Experimente mit Threads direkt auf der Konsole auszuführen ist also sicher eine gute Idee.
a = 0
def erhoehe():
global a
for i in range(100000):
a = a + 1
def erniedrige():
global a
for i in range(100000):
a = a - 1
import threading
erhoeher = threading.Thread(target = erhoehe)
erniedriger = threading.Thread(target = erniedrige)
erhoeher.start()
erniedriger.start()
erniedriger.join()
erhoeher.join()
print(a)
Die Variable a verändert sich nun nicht mehr. Aber warum hat sie nicht den Wert 0?
Atomare Anweisungen?
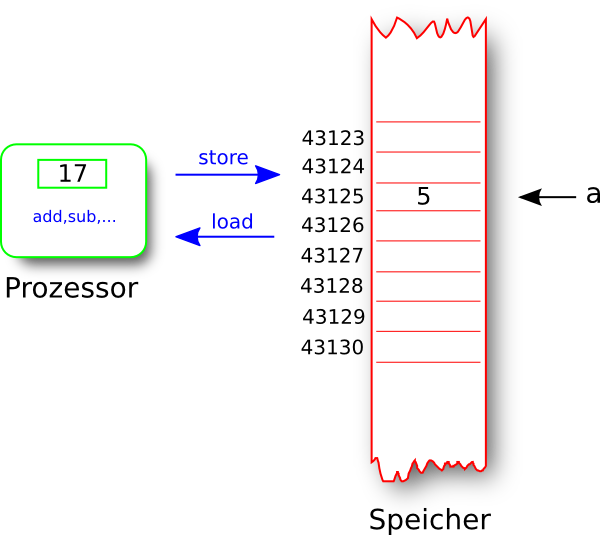
Die Anweisung a = a + 13 wird bei üblichen Architekturen in drei Schritten ausgeführt.
{kind=link}
{kind=link}
- load(43125) - Prozessorregister wird mit dem Inhalt der Speicherzelle 43125 geladen
- add(13) - zum Register wird 13 addiert
- store(43125) - Inhalt des Prozessorregisters wird in den Speicher geladen
Wir nehmen nun an, dass zwei Threads die Anweisungen a = a + 13 und a = a - 2 überlappend durchführen, z.B. so:
Thread1 Thread2
load(43125)
-----------------------------------------------------------------------
load(43125)
sub(2)
store(43125)
-----------------------------------------------------------------------
add(13)
store(43125)
Welche Werte nehmen Register und Speicherzelle nacheinander an? Was hätte Thread1, was Thread2 erwartet? Was ändert sich, wenn vor einer Unterbrechung die Register gerettet und nach der Unterbrechung restauriert werden?
'Erniedriger gegen Erhöher' - eine Lösung
Die Anweisungen a = a - 1 und a = a + 1 sind nicht atomar. Man muss dafür sorgen, dass sie nicht unterbrochen werden. Programmtechnisch kann man dafür sorgen, dass nur der Thread, der den Schlüssel hat, seine Anweisung durchführen darf. Nach Beendigung gibt er den Schlüssel frei. Ein eventuell wartender Thread kommt dann an die Reihe und besetzt seinerseits den Schlüssel.
a = 0
def erhoehe():
global a
for i in range(100000):
lock.acquire()
a = a + 1
lock.release()
def erniedrige():
global a
for i in range(100000):
lock.acquire()
a = a - 1
lock.release()
import threading
lock = threading.Lock()
erhoeher = threading.Thread(target = erhoehe)
erniedriger = threading.Thread(target = erniedrige)
erhoeher.start()
erniedriger.start()
erniedriger.join()
erhoeher.join()
print(a)
Der Quelltext zeigt, wie man ein zuvor geschaffenes Lock-Objekt entsprechend verwenden kann.
Timer 0
import threading,time
class Timer(threading.Thread):
def __init__(self,interval,routine):
threading.Thread.__init__(self)
self.interval = interval
self.routine = routine
def run(self):
time.sleep(self.interval)
self.routine()
class Ampel(object):
def __init__(self):
self.zustaende = ('rot','gelbrot','grün','gelb')
self.zustand = 0
self.enabled = True
self.timer = Timer(1.5,self.weiter)
self.timer.start()
def weiter(self):
self.zustand = (self.zustand+1)%4
print self.zustaende[self.zustand] # DEBUG
if self.enabled:
self.timer = Timer(1.5,self.weiter)
self.timer.start()
Timer
Im Modul threading gibt es eine Methode Timer.
Kleiner Test mit der Shell:
>>> a = Ampel() >>> gelbrot grün gelb rot gelbrot grün gelb rot gelbrot grün gelb rot gelbrot grün gelb a.enabled = False >>> rot
Beispiel 2
Im Beispiel werden zwei Threads p1 und p2 erzeugt, die sich nach Ablauf von dt Sekunden mit ihrer Nummer melden. Die Klasse TestThread erweitert den Konstruktor und implementiert die Methode run. run bestimmt das, was der Thread nach seinem Start tut.
# -*- coding: iso-8859-1 -*-
# Autor: mk, Datum: 31.5.08
import threading
import time
class TestThread(threading.Thread):
def __init__(self,dt,nr): # neuer Konstruktor
threading.Thread.__init__(self) # Aufruf des ererbten Konstruktors
self.dt = dt
self.nr = nr
def run(self):
time.sleep(self.dt)
print 'Thread: '+str(self.nr)
print 'Start Hauptprogramm'
p1 = TestThread(3,1) # neuer Thread 1
p1.start() # Start des Threads 1
p2 = TestThread(1.5,2) # neuer Thread 2
p2.start() # Start des Threads 2
p1.join() # warten, bis p1 fertig ist
p2.join() # warten, bis p2 fertig ist
print 'Ende Hauptprogramm'
Links
- Thread - wikipedia
- 18.4 Das Modul threading - aus 'Python' von Peter Kaiser, Johannes Ernesti
- 16.2 threading -- Higher-level threading interface - Python Library Reference
- PyThreads.pdf
- PyThreads.pdf
- The Little Book of Semaphores von Allen B. Downey
- Sync - Thread-Simulator